¶ What is DataSHIELD?
DataSHIELD is a privacy-preserving platform which allows the remote analysis of multiple data sources. It is privacy-preserving because it contains built-in mechanisms to prevent the user from viewing or copying individual-level data. Using the statistical programming language R, researchers write code which sends commands to each data source. These commands sent by the researcher are automatically checked to make sure they would not disclose participant data. If these checks are passed, summary statistics are returned to the researcher from each data source. These statistics include counts, means, standard deviations and the output from statistical models such as regression models. The output from each data source is automatically combined to also provide an overall summary of the data.
¶ How does it work?
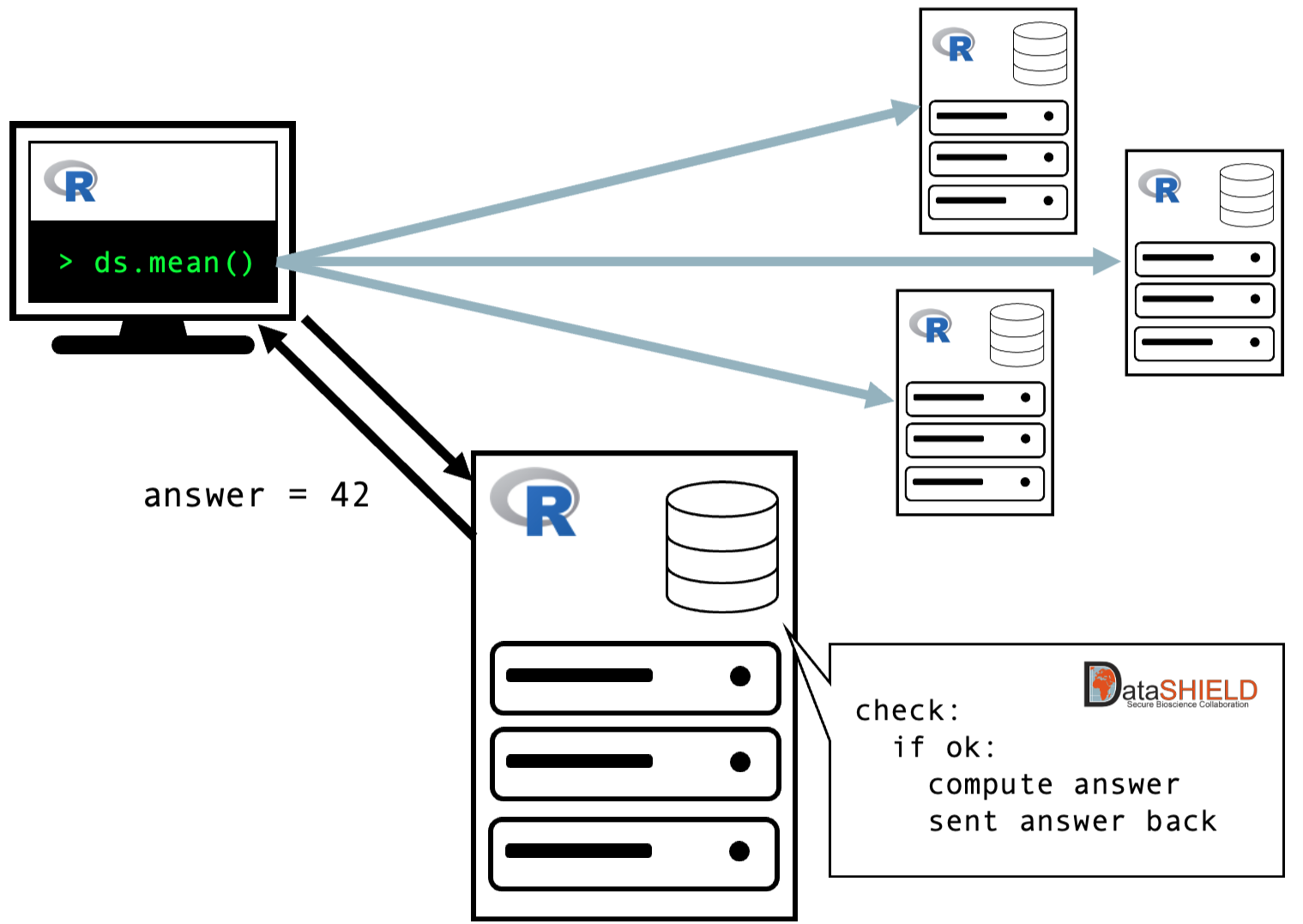
DataSHIELD packages consist of two components: client-side functions and server-side functions. The client-side functions are those used by the researcher, and the server-side functions are stored with the data and perform the analysis. The flow is as follows:
- The analyst logs in to each remote datasource using credentials provided by the data owners.
- The analyst writes a command in R using functions from DataSHIELD-specific client-side R packages. For example, the command
ds.mean("data$age")would request the mean of the variableagein the data framedata. - When this command is run, it sends a request to each data source to which the analyst is connected.
- Within each data source, a server-side version of the function is triggered. This function runs a command, and then check that the result will not disclose individual level data. If these checks are passed, it will return summary statistics to the user. In the current example, it will return the mean of the variable
agefor each data source. - The summary statistics returned from each data source will then be returned to the user, along with a combined statistic for all data sources.
¶ What are the safeguards employed?
The DataSHIELD commands contain built-in safeguards that are designed to stop individual pieces of data being returned to the analyst and instead return useful summary information. For example, a mean can only be calculated on more than 5 pieces of data to reduce the chances of a data item being revealed. Only commands that have been built into DataSHIELD and that have these safeguards can be run. Arbitrary R commands ("return row 6 of the data set") simply cannot be run in DataSHIELD. When the DataSHIELD command has been run at each location, the results are returned to the analyst (or an error message if something went wrong). More complex commands may involve several back-and-forth communications between client and server and additionally aggregation of results from the data sets.
It is important to stress that DataSHIELD functions are designed to enhance privacy, but don't guarantee privacy. A determined attacker can always exploit weaknesses. There is a balance between allowing data to be used for good and the amount of restrictions around its usage. We tend to hold the view that most researchers are not willfully malicious (they have a reputation to uphold) and as such we aim for "reasonable" measures of restriction.
¶ How do projects using DataSHIELD start?
The most common use case for using DataSHIELD is where a group of researchers have a shared research goal and have data to address the research. However, they don't want to centrally deposit the data or email around an analysis plan. Nor do they have existing Trusted Research Environments (TREs) to allow others to reach in and work with their data. This is not the only use case but the most frequent.
This diagram, taken from this paper, summaries some of the steps in the process that were used in the LifeCycle project

Additional parts of the process are:
- Agree the overall research aims, the types analyses that will be carried out and the process for granting access to data for research
- Get ethical and governance approval to use their data for the research
- Set up servers to run the software needed for DataSHIELD at each participating location (can happen in parallel with other tasks)
Each of these steps represent a large amount of work. Such is the initial activation cost that this approach is best suited to a group that intends to embark on a long term series of publications, as the subsequent analyses require less effort once the project is established.
Optionally the consortium might wish to build a catalogue and curate the metadata describing their datasets. This can be helpful (some would argue it is vital) for understanding what future research can be done and how data can be harmonised.
In this paper by Fortier and colleagues, these issues are also discussed with a particular focus on the harmonisation of the data.
¶ Who might be involved?
To get the project running requires a collaborative, interdisciplinary team of experts, orchestrated by a consortium manager:
- Researchers (epidemiologists, clinicians, scientists etc.)
- Developers / statisticians / data scientists
- Consortium managers / coordinators
- Consortium technical specialists
- IT staff or technical experts local to each participating data provider (institution)
- Data managers / custodians
- Ethics and governance experts
- Data protection people at each location
Developers / statisticians / data scientists are required if new analysis functionality needs to be built into DataSHIELD. Recall that each command or function that can be run in DataSHIELD has to be explicitly enabled and adapted to reduce the possibility of data leakage. There is more detail on how new functionality is built later on. They also support the researchers in running their analyses in a federated setting. A consortium manager or coordinator is needed to assemble the team and make sure it works in a coherent way. If possible, they should also ensure sustainability of the arrangements because otherwise the high set up costs are wasted if the consortium fades away after the initial funding expires. The consortium technical specialists are needed to guide the IT staff and technical experts that set up the infrastructure to hold each data set. A large part of this guide is designed to help them.... Ethics and governance experts are needed to help explain this novel way of working to those who are more used to authorising data releases or access to Trusted Research Environments (TREs). Hopefully, they can demonstrate that the safeguards designed to reduce the chances of individual data items leaving the hosting institution mean that a lighter weight data access agreement is needed. This is instead of a more bureaucratic data transfer agreement. Some of these that are relevant to the technical work warrant further explanation and are covered in more detail in the People and Organisation section.
¶ What about other platforms?
DataSHIELD is different from Trusted Research Environments (TREs), which allow users to log in to an isolated platform to work on each agreed data set. Typically these are run by an institution, and when a user has logged in they have full access to a particular data set using any analysis tool. This is an advantage for the user as they can use familiar statistics packages and it is easier to work with data that you see without restriction (DataSHIELD is much more limited on what you can do, and you can't see the data). To protect the the data, the user cannot remove results by email, FTP or cut and paste, but can take results out through an airlock where they are manually checked by a data custodian before being released. This manual checking process can be resource intensive (expensive) and subject to human error (data could be leaked). When an analysis uses different data sets held by different institutions, the user has to go through an approvals process for each TRE, run the analysis in the TRE and extract the results. They then have to combine results using meta analysis for an overall answer. There is no opportunity for analysing the data as if it were all pooled in a single location, which might be preferable to a meta analysis method.
Another class of systems allow the execution of pre-agreed analyses on each data set. Examples of these include Vantage6. These suffer from the problem that each party has to approve every analysis which can take time and effort. If a mistake is later found in the code, or the results prompt follow up question, the whole process starts again. Synthetic data can help resolve any potential issues before the pipeline is run, reducing the scope for errors and going through the approvals process.
Something about MHE or DP? Or accept that this is not covering these in detail - see forthcoming landscape review
¶ What about other methods?
From here: https://docs.google.com/presentation/d/1mgf14W4Eo7OMIUvf21EowaI4OQ7o-G4b/edit#slide=id.p20

Could also consider at a more detailed level, for example: Bitfount vs DataSHIELD vs Vantage6